
Boosting의 아이디어
- 여러 개의 Learning 모델을 순차적으로 구축해 최종적으로 합침(앙상블)\
- 여기서 사용하는 learning 모델은 매우 단순한(ex. 이진분류에서 0.5보다 정확도가 높은) 모델이다.
- 즉, 각 단계에서 새로운 base learner를 학습해 이전단계의 base learner 단점 보완
- 각 단계를 거치며 모델이 점차 강해진다 >> Boosting
AdaBoost(Adaptive Boosting)
- 각 단계에서 새로운 base learner를 학습해 이전 단계의 base learner의 단점을 보완
- Training error가 큰 관측치의 선택확률(가중치)를 높이고, training error가 작은 관측치의 선택 확률을 낮춤
- 오분류한 관측치에 집중한다: 정분류는 신경쓰지 않고 오분류한 것에 가중을 둔다
- 앞 단계에서 조정된 확률(가중치)를 기반으로 다음 단계에서 사용될 training dataset 구성
- 다시 첫 단계로 복귀
- 최종 결과물은 각 모델의 성능지표를 가중치로 해 결합(앙상블)

H1 Classifier: 보라색 선
알파 값을 구하는 이유: 각 관측치의 가중치를 업데이트 하기 위해서.(오분류한 데이터에만 가중치를 업데이트한다.)

H2 Classifier


해당 도형의 크기는 해당 관측치가 다음 단계의 학습 데이터셋에 선택 될 확률을 의미한다.
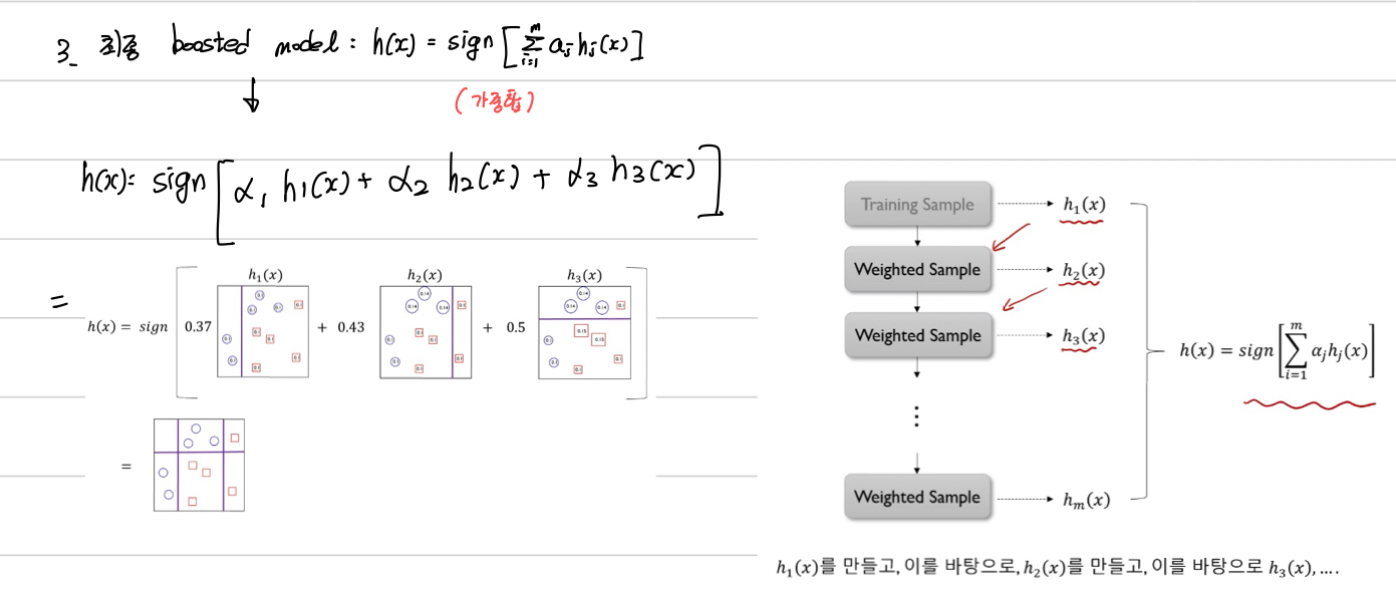
위 예제에서는 3번째 단계까지만 했다고 하면
h1(x), h2(x), h3(x)의 가중합을 하면 최종 boosted model이 도출된다.
이때, 가중치는 각각의 h(x)에서 구한 알파값.
Bagging vs Boosting

Gradient Boosting Machines(GBM)
- Gradient boosting = Boosting with gradient descent
- 첫 번째 단계의 모델 tree 1을 통해 Y를 예측하고, Residual을 다시 두번째 단계 모델 tree2를 통해 예측하고, 여기서 발생한 Residual을 모델 tree 3로 예측
- Residual: 실제 y값과 모델에서 도출된 y값과의 차이
- 점차 Residual 작아진다.
- Gradient boosted model = tree 1 + tree 2 + tree 3

Why gradient?


해당 게시글은 고려대학교 산업경영공학부 김성범교수님의 핵심 머신러닝 유튜브를 바탕으로 작성된 글입니다.