
불균형 데이터: 정상 범주의 관측시 수와 이상 범주의 관측치 수의 차이가 크게 나타날 때( + 클래스 별 관측치의 수가 현저하게 차이나는 데이터)
문제인 이유: 정상(다수)를 정확히 분류하는 것과 이상(소수)을 정확히 분류하는 것 중 이상(소수를 정확히 분류하는 것이 더 중요하다)

성능평가

위 문제에 대한 해결 방안
- 데이터를 조정: 샘플링 기법(Sampling Method)
- 언더 샘플링
- 오버 샘플링
- 모델을 조정:
- 비용 기반 학습(Cost sensitive learning)
- 단일 클래스 분류 기법(Novelty detection)
언더 샘플링(Undersampling)
다수 범주를 줄여 소수 범주의 개수와 비슷하게 만들자
Random Undersampling
다수 범주에 속한 관측치를 무작위로 줄인다: 매번 분류 경계선이 달라지는 단점이 있다.
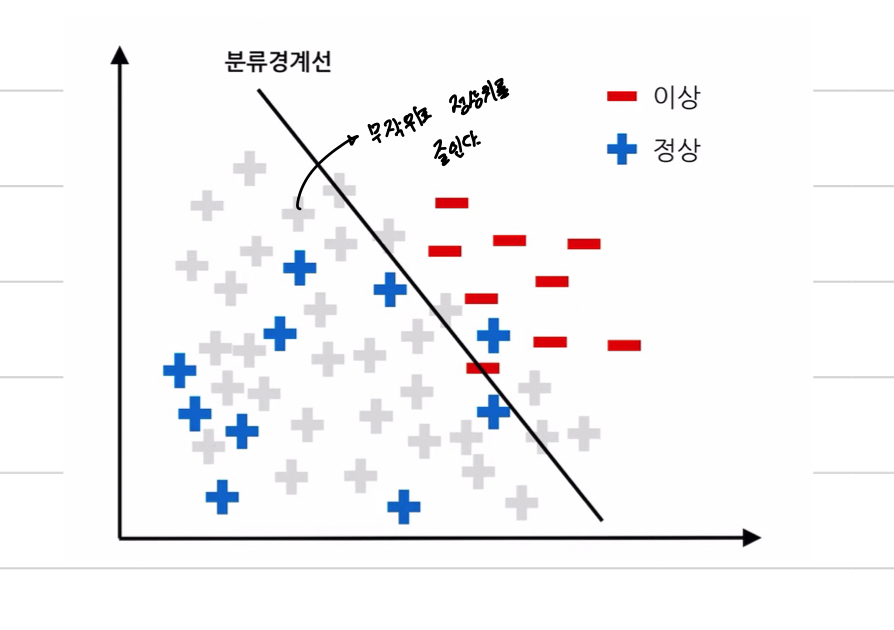
Tomek Links
두 범주 사이를 탐지하고 정리를 통해 부정확한 분류 경계선 방지

Tomek links 생성 후 다수 범주에 속한 관측치를 제거한다.

CNN(condensed nearest neighbor)
소수 범주 전체와 다수 범주에서 무작위로 하나의 관측치 선택해 서브데이터 구성
(1-NN은 파란색에 가까운 점은 파란색으로, 빨간색에 가까운 점은 빨간색으로 분류, K는 무조건 1로 해야한다.)
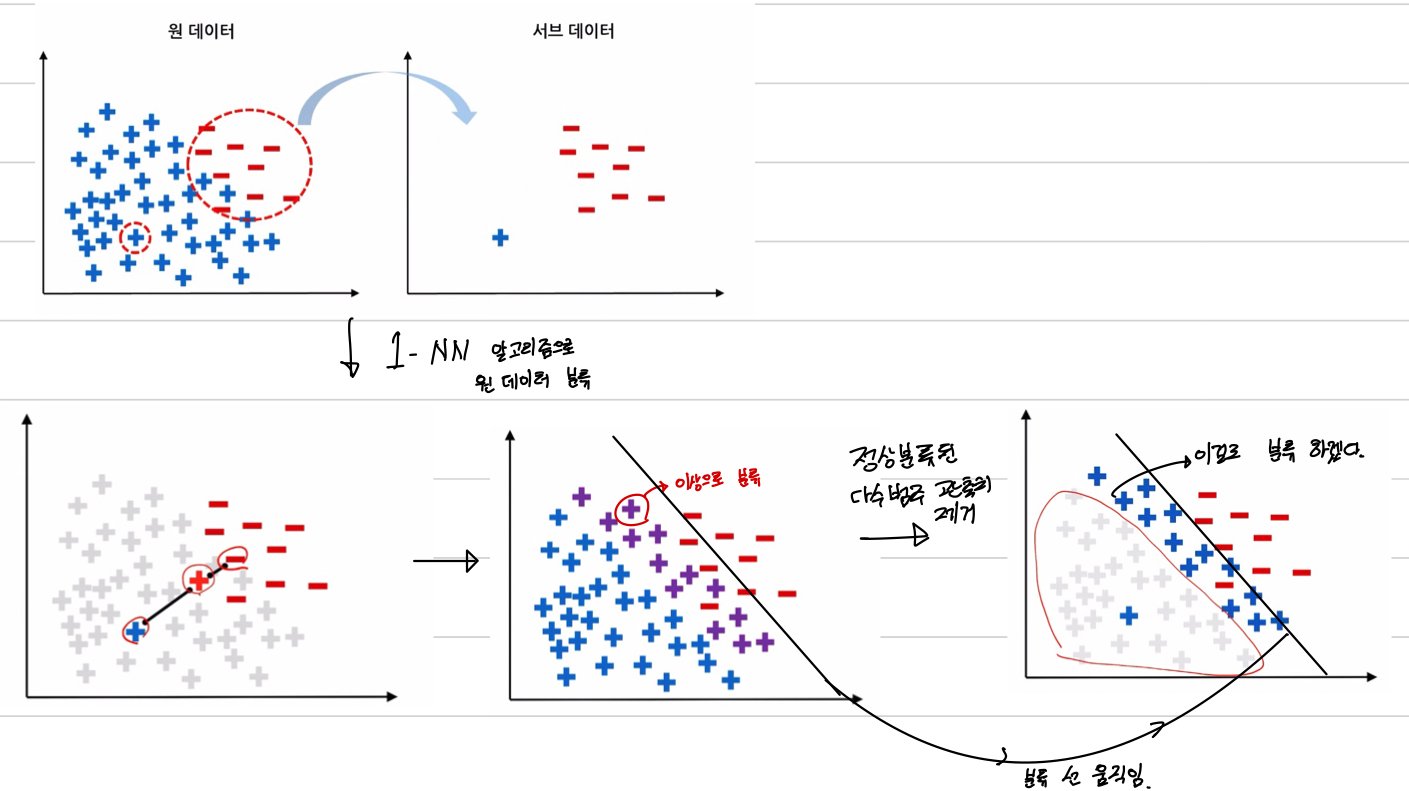
즉
- 소수범주 전체 + 다수 범주에서의 무작위 하나의 관측치 선택해 서브데이터 구성
- 서브데이터에서 1-NN알고리즘으로 분류
- 정상(파랑) 분류된 다수 범주 관측치 제거
- 재분류
OSS(One-side selection)
OSS = Tomek links + CNN

Tomek links는 border line만 지워지고 CNN은 완전한 정상쪽만 지워지기에 보완한 것
Undersampling의 장,단점
- 장점
- 다수 범주 관측치 제거로 계산 시간 감소
- 데이터 클랜증으로 클래스 오버랩 감소 가능
- 단점
- 데이터 제거로 인한 정보 손실
오버 샘플링(Oversampling)
Resampling
소수 범주 내 관측치를 단순 늘려보자

단점으로 소수 클래스에 과적합이 발생할 가능성이 있다.
보완책으로 가상의 관측치를 생성하는 것으로 해보자
SMOTE(Synthetic minority oversampling technique)
소수 범주에서 가상의 데이터를 생성하는 방법으로 K를 선택해야 한다.

소수 범주 내 모든 관측치에 대해 해당 과정을 반복해 가상 관측치를 생성한다.(K>= 2여야 한다. K = 1일때는 해당하지 않는다)
K = 1일때는 NN이 무조건 1개이므로 이상하게 생긴다.

Border line SMOTE
Border line 부분(정상 데이터와 이상 데이터의 경계선만) 샘플링을 해보자.
일단. border line을 찾아야 한다: 소수 클래스 Xi에 대해 K개 주변을 탐색 후 K개 중 다수 클래스의 수를 확인한다.

이후, Danger 관측치에 대해서만 SMOTE 진행한다.

ADASYN(adaptive synthetic sampling approach)
샘플링 하는 개수를 위치에 따라 다르게 하자

- 모든 소수 클래스에 대해 주변을 K개 탐색 후 다수 클래스에 대한 비율 구하기 : ri 구한다.
- ri >> ri hat 으로 스케일링
- G = 다수 클래스 개수 - 소수 클래스 개수, 스케일링 된 ri에 G를 곱한 후 반올림한다.
- 즉, ri hat x G 후 반올림 한 만큼 증폭시킨다.
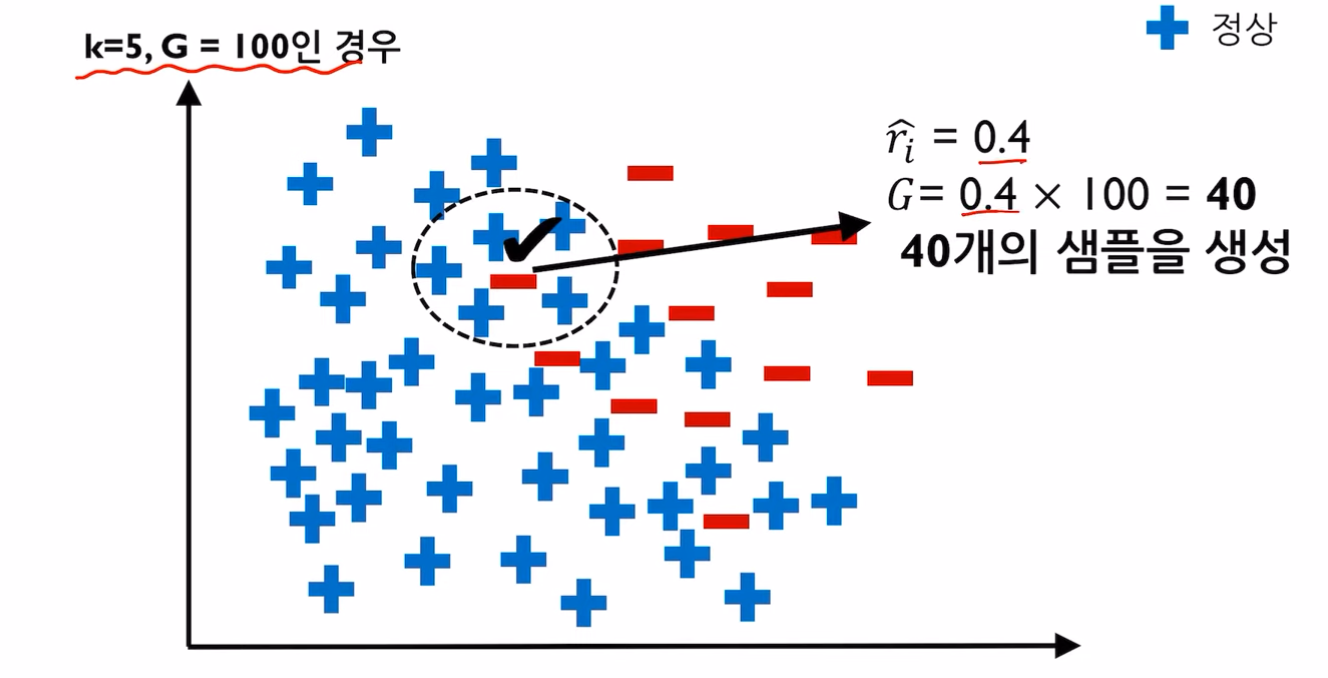

Borderline 뿐 아닌, 다수 클래스에 있는 데이테도 더 확인을 하자.
해당 게시물은 고려대학교 산업경영공학부 김성범교수님의 핵심 머신러닝 유튜브를 바탕으로 작성된 글입니다.