
Introducion to NLP:
자연어 처리
Syntax: 단어 사이의 구조적 관계
Semantics: 의미 분석
Pragmatics: 목표 달성을 위해 Language가 어떻게 쓰이는지
Lexical Analysis: 어휘 분석
Syntax Analysis: 구문 분석
End to End Multi-Task Learning: 종단학습, 즉 사람의 개입이 없이 학습한다.
>>> 문서와 Output만 주어지면 사람의 개입 없이 처리하는 Model을 만들겠다.
Lexical Analysis: 어휘 분석
: 일정 단어 또는 토큰 수준, 즉 의미를 보존할 수 있는 최소한의 수준에서 분석을 진행하는 것
목적: 일정한 순서가 있는 characters의 조합을 sequence of Token으로 변환하기.
- 형태소 분석이 기본 (morpheme)
- 단어 관점에서 토큰을 사용하기도 한다.
Process
- 문장 구분하기: Sentence Splitting >> 문장의 종결 부호, 3.14, 이러한 종결 부호만으로 구분할 수 없다.
- Tokenization : 의미를 가진 최소의 단위
- word tokens, number tokens, space tokens
- 각각의 Tokenization마다 다른 Token이 나온다.
- Tokenization은 매우 어려운 과제이다.
- Morphological Analysis: 형태소에 따른 변종들이 존재한다. 의미를 훼손하지 않는 내에서 차원을 줄여야 한다.
- Stemming : 단어의 Base Form 찾는 것으로 진짜 단어가 아닐 수 있다.
- ex) Love, Loves, Loved, Loving >> Lov
- 다른 단어가 하나의 stem으로 나올 수 있는 단점이 있다. ex) army, arm >> arm, stocks, stockings >> stock
- Lemmatization: 품사가 보존되는 원형 단어를 찾기. 즉, 진짜 단어를 찾아 오류가 적다. 의미분석이 중요할 때 자주 쓰인다.
- ex) Love, Loves, Loved, Loving >> Love
- 속도가 느리다.
- Stemming : 단어의 Base Form 찾는 것으로 진짜 단어가 아닐 수 있다.
- Part-of-Speech (POS) tagging : 각각의 토큰이 문장에서 어떤 형태소를 가지고 있는지?
- Sentence X에 대해 각각 Token에 따른 형태소 Y를 도출한다.
- 같은 token이여도 의미, 상황에 따라 다른 형태소를 가질 수 있다.
- Tagging algorithm: learned paramter using texts. 약 96%의 높은 정확도가 같은 도메인 내에서 나와야 한다
- Decision Trees
- Hidden Markov Models
- SVM
- CRF: 현재도 SOTA
- 이러한 전통적 모델이 Deep Learning 전에는 자주 사용됐다.
- 추가 analysis. ex) 객체명 인식, sentence split, chunking..
Syntax Analysis
: 일련의 문장이 들어올 때 문법의 형식에 맞게 분석하는 과정


어휘적 모호성(Lexical ambiguity)는 구조적 모호성(structural ambiguity)를 나타낸다.
Other Topics in NLP
Language Modeling
: 특정 단어들의 sequence(문장)에 따른 확률을 매기는 것. 생성된 문장이 실제 언어,문법적 관접에서 봤을 때 그럴듯한 문장인지 판단하기 위해 확률을 준다. 문장 그 자체에 확률이 생긴다.
- Machine Translation
- ex) P(high wind tonight) >> P(large wind tonight)
- Spell correction
- The office is about fifteen minuets from my house
- P(about fifeen minutes from) >> P(about fifteen minuets from)
- Speech recognition
- P(I saw a van) >> P(eyes aws of an)
- Summarization, question-answering, etc
Pre-trained model인 ELMo, GPT 등이 모두 Language Modeling을 바탕으로 만들어진 것

Markov Assumption
문장에서 마지막 단어를 예측하는 모델에서, 앞에 존재하는 모든 단어들이 주어져야 한다. 이때 경우의 수가 찾기 매우 어렵다.
p(W1), P(W2 | W1)까지는 구하기 쉬워도, P(W10 | W1,W2 .....W9)을 찾기는 매우 어려울 것이다
.
그렇기에 Unigram model을 만들어 사용하자. Unigram model: Language model에서 각각의 단어는 독립적으로 등장했다고 한다.

Bigram Model
Condition은 단순히 이전 단어에만 영향을 받는다고 한다.
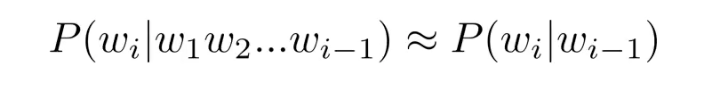
N-grams models
- 이를 trigrams, 4-grams, 5-grams 등으로 확장시킨다.
- 언어 자체가 longdistance dependencies가 있으면 나타내기 어렵다
- ex) "The computer when I had just put into the machine room on the fifth floor crashed."
- 언어 자체가 longdistance dependencies가 있으면 나타내기 어렵다
Neural Network-based Language Model
Neural Network를 통해 Language Model을 만드려고 했다.
- RNN,기반
해당 게시글은 유튜브 고려대학교 산업경영학부 강필성 교수님의 DSBA 연구실 유튜브 영상을 바탕으로 작성된 글입니다.
https://www.youtube.com/watch?v=NLaxlUKFVw4&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=3
https://www.youtube.com/watch?v=DdFKFqZyv5s&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=4
https://www.youtube.com/watch?v=NLaxlUKFVw4&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=5