
Count-based Representations
: 가변적 길이의 문장을 고정된 길이의 숫자형 벡터로 변환하는 기법
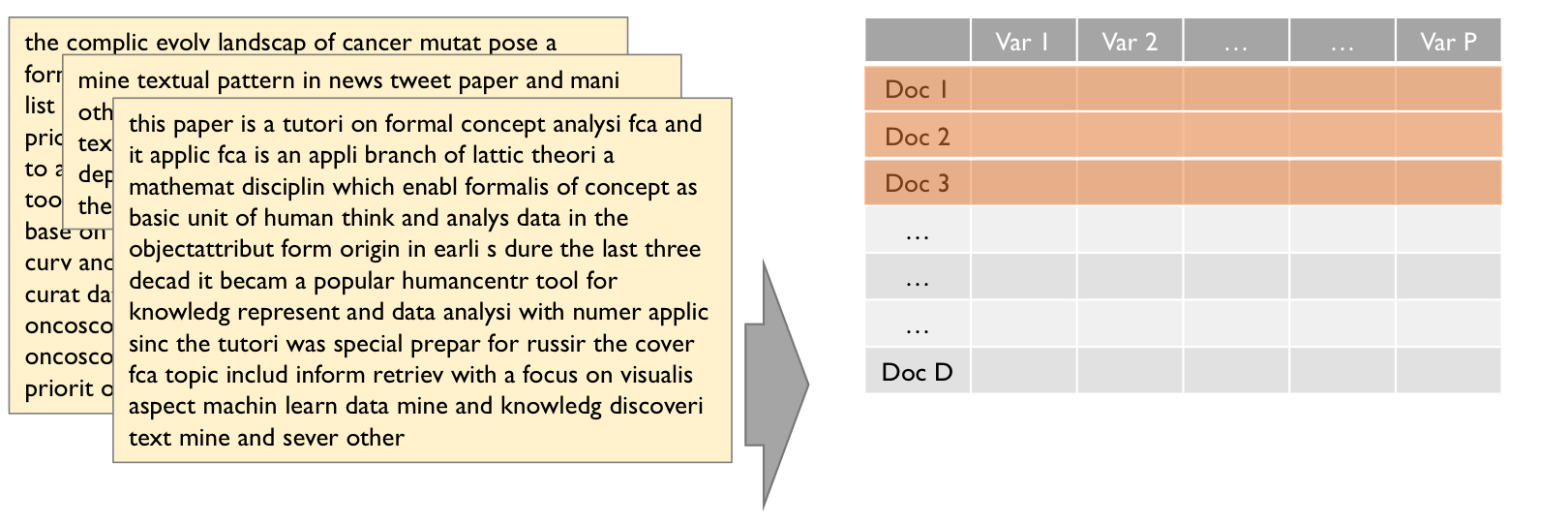
모델에 Input으로 들어가는 X는 길이가 모두 같은 벡터여야 한다(Vector Space Model).
하지만 텍스트 분석에서 대부분의 문서의 길이 (len(X1), len(X2) ..etc)는 다르다.
해당 게시글에서는 단어의 빈도 기반으로 적용하는 법에 대해 서술한다.
즉, 목적은 Preprocessed 된 Text data, 즉 unstructured data를 structured data(vector/matrix 형태) 로 변환하는 것이다.
Bag of Words
- 문서는 단어들의 집합체이며 해당 단어의 순서는 무시한다고 가정한다.
- 단어가 다르면 개별 단어를 atomic symbol로 고려하고, 이를 discrete space에 표현한다.
문서에서 한번이라도 등장한 단어를 모두 나열 후 해당 단어가 등장한 횟수만큼 표기를 한다.
Term-Document Matrix
- Binary representation: 해당하는 단어의 등장 횟수에 관계 없이, 등장 여부만 고려
- Frequency representation: 해당하는 단어의 등장 횟수(빈도)를 고려한다.

Idea
- Contents는 단어의 등장 빈도수로 추론할 수 있다.
- 하지만, 단어의 순서를 고려하지 않는 큰 단점이 존재한다. 그렇기에 우리가 보는 단어는 독립적인 Feature이다.
- Visual words = independent feaures 라는 단점.
- ex) John is quicker than Mary = Mary is quicker than John in Bag Of Words Representation
- Reconstruct가 잘 안된다. Original Text를 Term-document matrix로 변환 후, Term-document matrix로 Original Text를 복원하는 것은 힘들 단점이 있다.

Stop Words
Bag Of Words에서 단어에 해당하지만, 정보를 담고있지 않는 단어를 의미한다. 문법적인 역할만 수행
ex) 관사, 종결어미, 접속사 등
- 대문자의 경우 소문자로 변환
- 문장 기호 제거
- 숫자의 경우 도메인에 따라 중요도가 다르기에 도메인을 고려해야한다
TF-IDF
특정 단어가 해당 문서에서 중요한 정도를 판단: 단어에 가중치 부여
TF: Term-Frequency (빈도)
The number of times that the term t occurs in the document d
(해당하는 특정 문서 d에 term t가 몇번 등장했는지)
DF: Document Frequency
The number of documents in which the term t appears
(전체 corpus에서 term t가 등장한 문서의 수)
- 빈번하게 등장하지 않는 단어가, 특정 문서에서 중요할 것이라는 가정.
- is, can, the, of와 같은 단어는 빈번하기에 중요하지 않다.
- 그렇기에 DF를 역수로 취해 (IDF) 빈번하지 않게 등장하는 단어에 가중치를 준다.
IDF: Inverse Document Frequency

N: 문서의 개수
df_t: term t에 대한 Document Frequency
TF-IDF
TF는 높고, DF는 낮아야 한다. 즉, TF * IDF가 크도록 만들어야 한다.

N-Grams
TF-IDF 확장
Language Model의 경우 N-1까지의 단어를 보고 N번째 단어를 예측한다.

Text Mining에서의 N-Gram은
- 복합어(두 단어 이상으로 이루어진 phrase)가 유의한 의미를 가질 때 유용하다.
- Six sigma, big data, etc.
해당 게시글은 유튜브 고려대학교 산업경영학부 강필성 교수님의 DSBA 연구실 유튜브 영상을 바탕으로 작성된 글입니다.
https://www.youtube.com/watch?v=DMNUVGbLp-0&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=6