
저자들의 주장
- Pre-trained word representations: Down stream tasks에서 가장 Key point
- 복잡한 특성의 모델링 가능할 수 있어야 한다.(구문분석, 의미분석 모두)
- 다의어의 관점에서 하나의 언어가 상황에 따라 다르게 Embedding 된다.
ELMo
- 각각의 Token은 전체 Input sentence에 의한 representation
- ELMo에서 사용하는 Embedding vector는 bidirectional LSTM에서 추출된다.
즉, ELMo는 전체의 입력 문장을 이용한 representation이고, 입력 문장은 bidirectional LSTM으로 Language model을 학습시켰다.
**Language model(언어 모델): 문장의 확률을 나타내는 모델로 문장 자체의 확률을 예측하거나, 다음 단어 예측과 같은 downstream task 수행 가능.
특징
ELMo는 bidirectional LSTM의 모든 hidden vector를 결합해 사용한다. 특정 층에 해당하는 값을 사용하는게 아니다.

각각의 층마다 용이한 task가 다르므로 수행하고자 하는 task에 따라 유연한 모델링이 가능하다.
ELMo는 Language Modeling을 사용한다.
**Language modeling: 지금까지 주어진 단어의 sequence로 다음 단어를 예측한다.
P(W_t | W_t-1, W_t-2, W_t-3)
ELMo 학습법
Forward Language Model + Backward Language Model 모두 학습한다.

즉, Forward와 Backward 모델 학습 후,
- 해당 단어에 대해 위치가 같은 hidden_vector를 concat한다.
- 특정한 Task에 따라 각각의 Layer에 대한 가중 합 계산: downstream task에 따를 parameter이다.
- ELMo에 대한 embedding값 생성된다.

ELMo for downstream task
ELMo를 만드는게 문제가 아니라, pretrained된 vector로 downstream task를 해결해야 한다.
bidirectional LSTM에 문장을 넣어 일단 각각의 Forward, Backward 학습시키고 hidden vector 생성한다.

bidirectioanl language models
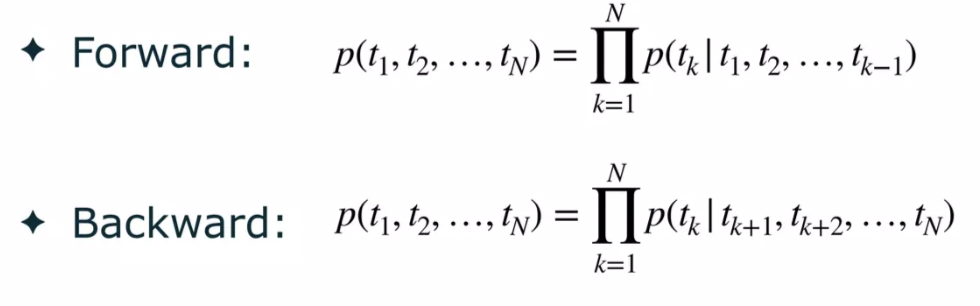
Forward LSTM의 top layer output은 다음 token t_k+1을 예측하는데 사용된다.

이렇게 forward와 backward에 대해 모두 학습이 되면, 각각의 token_k에 대해 bidirectional LM은 2L+1개의 표현을 나타낸다.
(L = layer 수)

ELMo Embedding 사용법/위치

해당 게시글은 유튜브 고려대학교 산업경영학부 감필성 교수님의 DSBA 연구실 ELmo 영상을 바탕으로 작성된 글입니다.
참조글: