
Transformer:
RNN과 다르게 한번에 모든 토큰을 처리한다. 즉, Attention 사용 + 속도가 매우 빠르다.

Transformer의 구조
- Encoder: 한번에 모든 Sequence를 사용해 Unmasked 구조이다.
- Decoder: 생성 시 순차적으로 처리해야하므로 순서에 따라 Masked 구조이다.
Encoder, Decoder component: 여러개의 Layer을 반복적으로 Stack 쌓음.
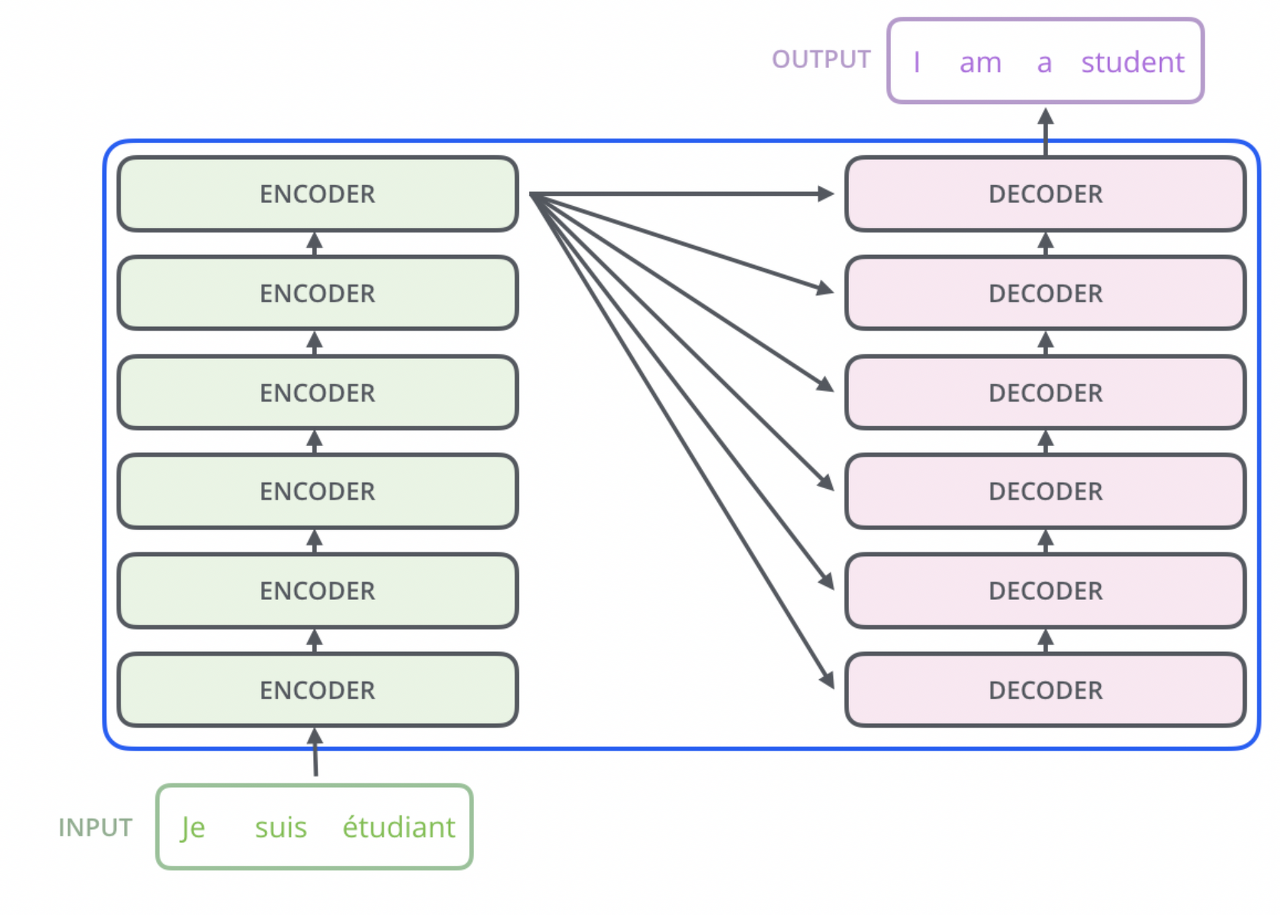
- Encoder: 2단구조( Self Attention Layer + Feed Forward Neural Network)
- Self Attention Layer: Token 처리 시 함께 주어진 다른 Input들을 얼마나 중요하게 볼 것인지에 대한 계산. 이때 단어의 Position은 그대로 적용된다.
- Feel Forward Neural Network: 각각의 Self Attention이 수행된 단어들에 해대 Neural Network 적용해 Output 추출. 역시 Position은 그대로 적용된다. 즉, 단어 하나하나끼리 Self -attention, FFD 따로 진행.
- 즉, 각각의 모든 Token에 Self Attention 계산 후, Feed Forward Neural Network 적용해 Output을 추출한다
- Decoder: 3단구조( Self Attention Layer + Encoder-Decoder Attention + Feed Forward Neural Network)
- Self Attention Layer: Decoder에서 어떤 정보가 주어지면 자기 자신끼리 Self Attention 수행한다.
- Encoder -Decoder Attention: 최종 Output 산출 시, Encoder에서 주어지는 정보를 어떻게 반영 할 것인지? 즉, Encoder에서 가져온 정보와의 Self Attention 수행
- Feed Forward Neural Network를 통해 Output 추출
Input Embedding
제일 처음 Encoder의 입력으로 사용된다. 1차적으로 Input 단어들에 대해 Embedding 적용 후 보통 512차원으로 적용.
다음 층의 Encoder등의 입력은 이전 Encoder의 Output을 사용한다. 이때 사이즈(Hyper Parameter)는 유지된다.
Positional Encoding
전체 sequence를 한번에 Input에 넣으면 특정 단어가 언제 입력됐는지에 대한 정보가 손실된다.(위치 정보가 손실된다)
그렇기에 각각의 위치를 보존 해주기 위해 Positional Encoding 사용한다.
즉, Input Embedding + Positional Embedding (Concat이 아닌 요소별 덧셈)
Positional Encoding의 조건
- 해당하는 Positional Encoding vector 자체의 크기는 같아야 한다.
- 위치관계 표현이니 두 단어의 거리가 Input sequence에서 멀어지면 Positional Encoding 사이의 거리도 멀어져야 한다.
Self Attention
이렇게 Input Embedding과 Positional Encoding을 통해, Encoder에 Input으로 들어왔다고 한다.
Encoder의 Self Attention에서는 각각의 Token에 대해 Dependency가 존재한다.
Feed Forward Neural Network에는 Dependency가 존재하지 않는다.

그렇다면 예를 들어 "The animal didn't cross the street because it was too tired"
위 문장에서 "it"을 "The animal"에 Self Attention을 이용해 연결시킬 수 있다.
- Self Attention은 Input sequence의 다른 단어들을 모두 살펴보며 "it"과 연관이 있는 단어에 대한 답을 구하는 과정이다.
- 즉, 다른 단어들의 관계를 알기 위해 현재 동일한 Input sequence의 다른 단어들을 살펴보겠다는 의미이다.
Query, Key, Value
Self Attention 계산 위해 각각의 단어마다 Query, Key, Value 벡터를 생성한다.
- Query: 현재 내가 보고 있는 단어. 다른 단어의 Scoring을 위한 기준이 된다.
- Key: Label의 의미. Query가 주어졌을 때 유의미한 관계(relevant)의 단어를 찾을 떄 Key를 바탕으로 먼저 찾는다
- Value: Key에 딸려있는 실제 값

Query, Key를 통해 가장 적절한 Value를 찾아 연산하겠다.
Query, Key, Value 생성 방법:
Input Embedding에서 나온 벡터에 WQ, WK, WV matrix를 곱해 생성한다. 해당 W는 Weight로 추후 구해야 한다.

보통, Q,K,V의 차원은 Input, Output보다 작게 한다.
Self Attention 계산법
현재 보고 있는 Query가 가장 관련이 높은 Key와 Value를 찾아야 한다.
- 현재 Query와 연관성 큰 Token 찾는 법: 현재 Query vector(q1)과 나를 포함한 나머지 값들의 Key(K(n))을 곱한다.
- Root(차원 수)로 나눈다. (Gradient Stable 위해)
- Softmax Score 도출: 해당 Position에 대한 단어가 현 Query vector(q1)에 얼마나 중요한지 판단
- Softmax score * Value >> Value가 N개이면 N개의 값 도출
- Softmax 에 의해 가중합이 된 Value값들을 모두 더한 값을 첫 번째 Token의 Self Attention Output(z1)으로 사용한다.


Multi Head Attention
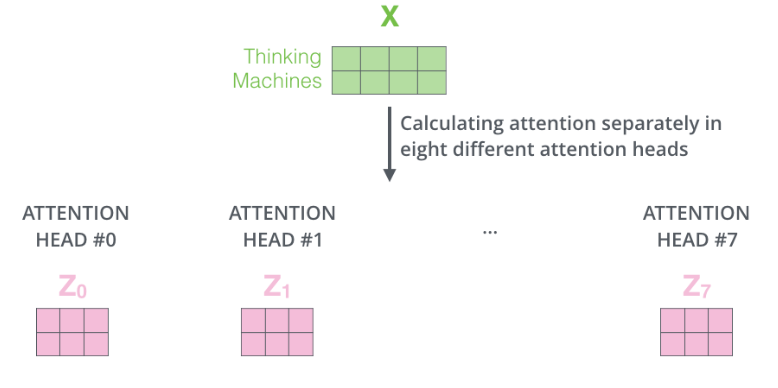
Attention 자체도 서로 다르게 줄 수 있으니 "It"이 어떤 단어를 볼지에 대해 하나의 경우의 수가 아닌, 여러개의 경우의 수를 사용했을 때, 다음과 같이 8개의 Attention Head를 생성할 수 있다.
위와 같이 8개의 행렬 결과값이 나온다고 Feed ForWard Layer로 보낼 수 없다. Feed Forward Layer은 한 위치에 대해 하나의 행렬만을 input을 받을 수 있기에 해당 8개의 Attention Headf를 하나의 행렬로 합쳐야 한다.
- Self Attention의 Output(Attention Head #(0~7) = Z(0 ~ 7))들을 Concat 한 것과 같은 수의 컬럼, 그리고 원래의 Embedding과 같은 행의 수를 가진 W0 matrix를 생성한다.
- Concat한 Z(0~7) * W0

Add Residual & Normalization
Input에 대해 Self Attention을 적용한 후, Residual Block을 더하고 Normalization 적용해야 함.
Residual Block: 어떤 입력의 Output(f(X))에 자기 자신(X)을 더해주는 것: f(X) + X
이를 통해 gradient가 사라지지 않게 해준다.

Add & Normalize는 모든 Encoder와 Decoder에 사용한다.
Poinsition-wise Feed Forward Network
- 개별의 Position별 Feed Forward Network를 적용해야 한다.
- FFN(x) = max(0,x * W1 + b1) * W2 + b
- 각각의 Layer마다 다른 parameter 사용한다.
같은 Encoder Block 내에서의 FFD는 같은구조이다. 즉, 같은 block 내에서 동일한 FFD

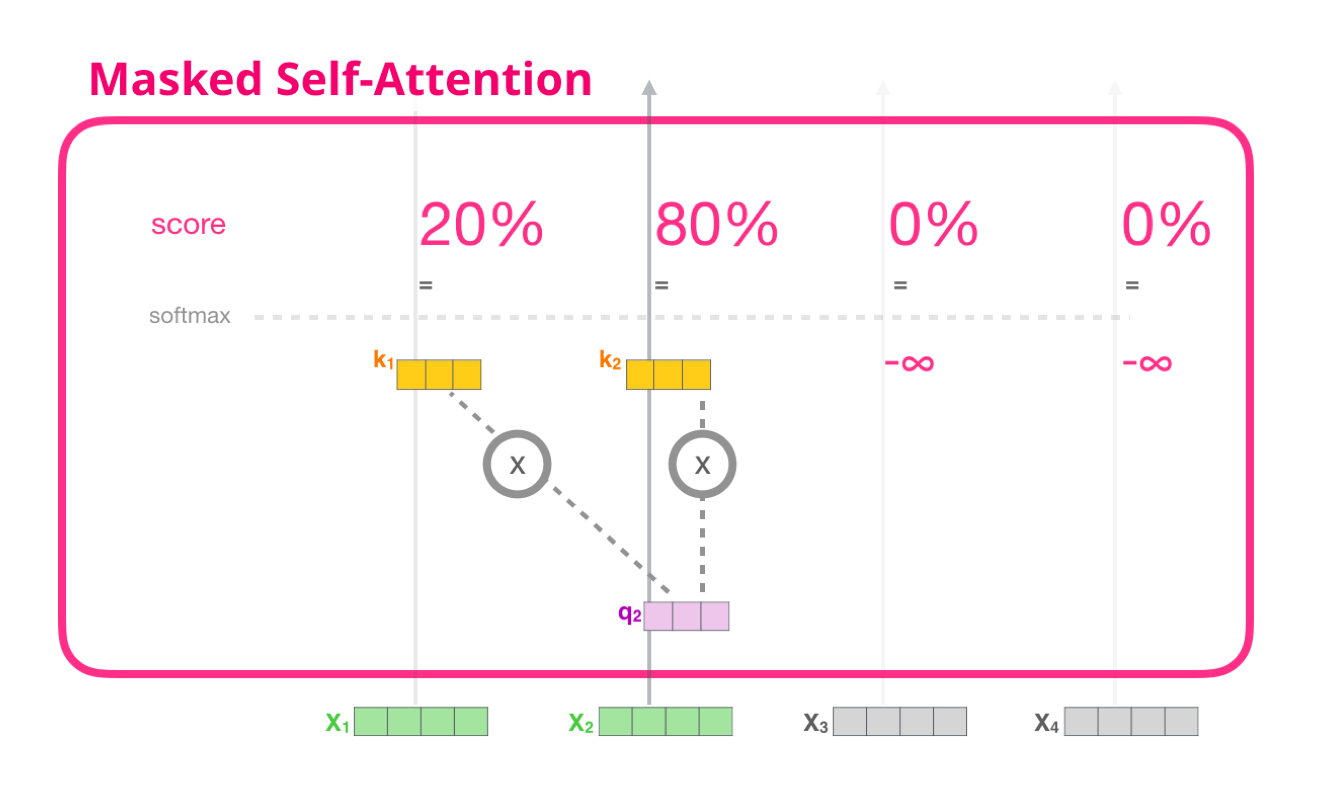
Decoder : Masked Multi Head Attention
Decoder에서 Self Attention Layer은 반드시 자기 자신보다 앞쪽 Layer에 있는 Token들의 Attention Score만 볼 수 있다.
그렇기에 뒷쪽 Token들의 Self Attention Score를 -inf로 보내면 된다.

Decoder: Multi Head Attention with Encoder Outputs
Encoder의 Output과 Decoder의 Masked Multi-Head Attention을 통과한 값 사이의 Multi Head Attention
Linear & Sofrmax Layer
Decoder들을 거치고 최종적으로 남은 벡터를 단어로 바꾸는 과정
- Linear Layer: Decoder가 마지막으로 출력한 벡터를 더 큰 사이즈의 벡터로 투영시킨다
- Sofmax Layer: 최종적 Argmax로 단어 출력.

해당 게시글은 유튜브 고려대학교 산업경영학부 DSBA 연구실의 Transformer 영상을 바탕으로 작성된 글입니다.