1-1 신경망 네트워크의 구성
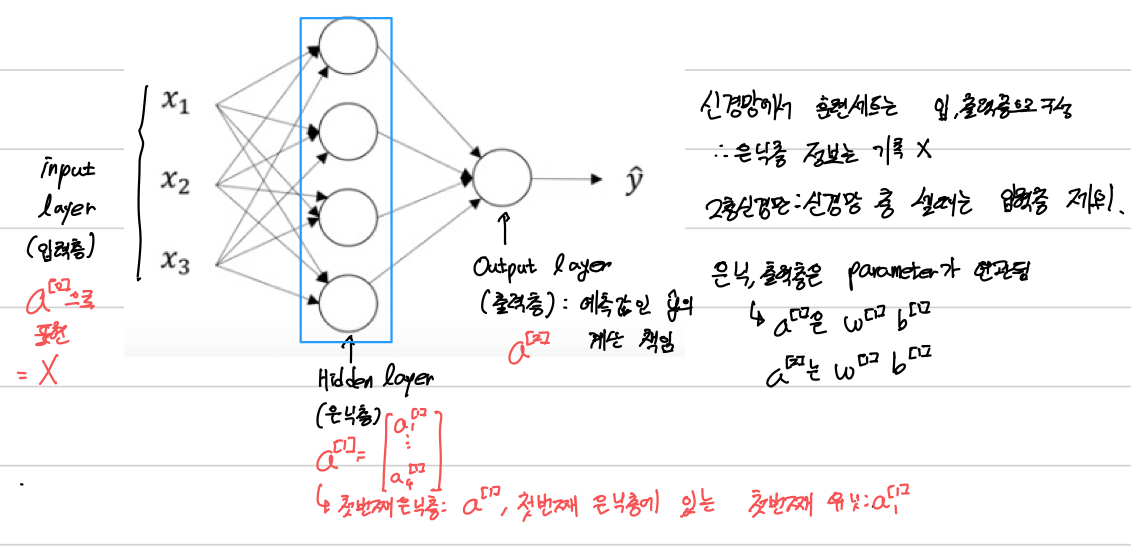
1-2 신경망 네트워크의 출력의 계산

1-3 많은 샘플에 대한 벡터화

1-4 Activation Funcation
신경망에서 은닉층과 출력층에 어떤 함수를 써야 할지 결정을 해야한다. 대표적인 4개의 함수는 다음과 같다.

Sigmoid와 Tanh는 Z의 값이 너무 크거나 작아지면 기울기가 0에 수렴하는 단점이 있다.
또한 이진분류 출력층을 제외하고는 대부분 Sigmoid 보다 Tanh함수가 효율적이다.
이진분류의 출력층을 제외하고선 대부분 Relu 함수를 사용한다.
+ 위와 같은 비선형 함수를 써야하는 이유: 선형함수 사용 시 은닉층을 쌓아도 아무런 혜택이 없을 수 있다.

1-5 신경망 네트워크와 경사 하강법

또한 신경망을 훈련시킬 때 W의 초기값이 0이 아닌 랜덤 변수로 측정해야한다.
W의 초기값이 0이라면 dw를 훈련시켰을 때 모든 hidden unit이 동일해지기 때문에 의미가 없어진다.

2-1 더 많은 층의 심층 네트워크
Logistic Regression은 매우 얕다. Hidden units가 많을수록 모델은 Deep 해진다. 이때 얼마나 Deep한 신경망을 사용할지 예측하는 것은 매우 어렵다.

L = 4 (Layer의 수)
2-2 정방향 전파와 역방향 전파


2-3 심층신경망에서 정방향 전파

2-4 행렬의 차원을 알맞게 만들기
디버깅 시 차원 확인하면 편리하다.

2-5 심층 신경망이 더 많은 특징을 잡아내는 이유
1. 낮은 층에서는 간단한 특징을 잡아내고, 깊은 층에서는 탐지된 것 바탕으로 복잡한 특징을 찾는 것이 가능하다. ex) CNN
2. 회로이론에 의해, 은닉층의 개수가 작지만 깊은 심층 신경망에서 계산할 수 있는 함수가 있다. 하지만 깊지 않으면 은닉층이 너무 많아야 한다.
해당 내용은 네이버 부스트코스 Andrew NG의 딥러닝 1단계: 신경망과 딥러닝 을 바탕으로 작성된 글입니다.