1. 최적화 알고리즘
1-1. 미니 배치 경사하강법(Mini-Batch Gradient Descent)
배치 경사하강법(Batch Gradient Descent)는 모든 전체 훈련세트를 한번에 처리하기에 매우 오래걸린다. 한 단계의 업데이트를 위해 전체 훈련세트를 고려해야 한다.
이때 훈련 샘플을 작은 '미니배치' 라는 훈련 세트로 나눈다.
예를들어 5000000개의 훈련 세트에서 사이즈가 1000인 미니배치이면면 5000개의 미니배치가 생긴다.


1-2. 미니 배치 경사하강법 이해하기

Batch Gradient Descent에서의 비용함수 J는 모든 iteration에 대해 감소해야 한다. 증가하면 잘못된 것이다.
하지만 Mini-Batch Gradient Descent에서는 비용함수 J가 감소되는 경향을 보이지만 노이즈가 발생한다.
(다른 미니배치들에서 계산하기 때문)
미니배치 사이즈의 크기를 항상 잘 선택해야 한다.
훈련 세트 <= 2000: Batch Gradient Descent
훈련 세트 > 2000: Mini-Batch Gradient Descent
이때의 Typical Mini Batch Size: 64,137,256,512와 같은 2의 제곱수를 보통 사용한다.
(미니배치의 사이즈가 너무 크거나 작지 않아야 속도 및 정확성이 높아진다)
1-3. 지수 가중 이동 평균(Exponentially Weighted Average)

지수 가중 이동 평균은 최근의 데이터에 더 많은 영향을 받는 데이터의 평균 흐름을 계산하기 위해 지수 가중 이동 평균을 구한다.
B 값은 하이퍼파라미터로 최적의 값을 찾아야하며 보통 0.9를 사용한다.
vt: 1/1-B기간 동안의 평균 기온
ex) B = 0.9 : 10일간의 기온 평균
B = 0.5: 2일간의 기온 평균
특징:
- 최근 데이터에 가중치 부여해 시간에 민감한 변화 잘 감지한다.
- 이전 데이터의 영향을 지수적으로 감소시켜 데이터의 노이즈를 완화하며 추세를 부드럽게 할 수 있다. 이상치에도 덜 민감하게 할 수 있다.
1-4. 지수 가중 이동 평균 이해하기

결국, v100을 기준으로 보면 지수적으로 감소하는 그래프가 나타난다. v100은 각각의 요소에 지수적으로 감소하는 요소를 곱해서 더했기 때문.
이때 위 그림의 마지막 B와 입실론의 식으로 얼마의 기간이 이동하면서 평균이 구해졌는가에 대한 값을 얻을 수 있다.
1-5. Momentum 최적화 알고리즘
Momentum 최적화 알고리즘은 경사에 대한 지수가중 평균을 계산 후 가중치를 업데이트 한다.

Momentum 알고리즘은 매 단계의 경사 하강 정도를 부드럽게 만들어준다.
관성 즉, 과거의 방향성을 기억해 반영한다.
1-6. RMSProp 최적화 알고리즘

즉, S_dw는 도함수의 제곱을 지수가중평균하는 것이다.
수평 방향에서는 빠르게 움직이고, 수직 방향에서는 느리게 혹은 진동을 줄이는 것이 목표이다.
결국, s_dw는 작고, s_db는 크게 만들어야 하며 그렇게 된다(수직으로 크게 움직이고 수평으로 조금 움직이기 때문)
이에 미분값이 큰 곳에서는 업데이트 시 큰 값으로 나누어 기존 학습률보다 작은 값으로 업데이트해 진동을 줄여준다. 반면, 미분값이 작은 곳에서는 업데이트 시 작은 값으로 나눠주기 때문에 기존 학습률보다 큰 값으로 업데이트 해 빠르게 수렴하도록 한다.
1.7 Adam 최적화 알고리즘
Adam = Momentum + RMSProp

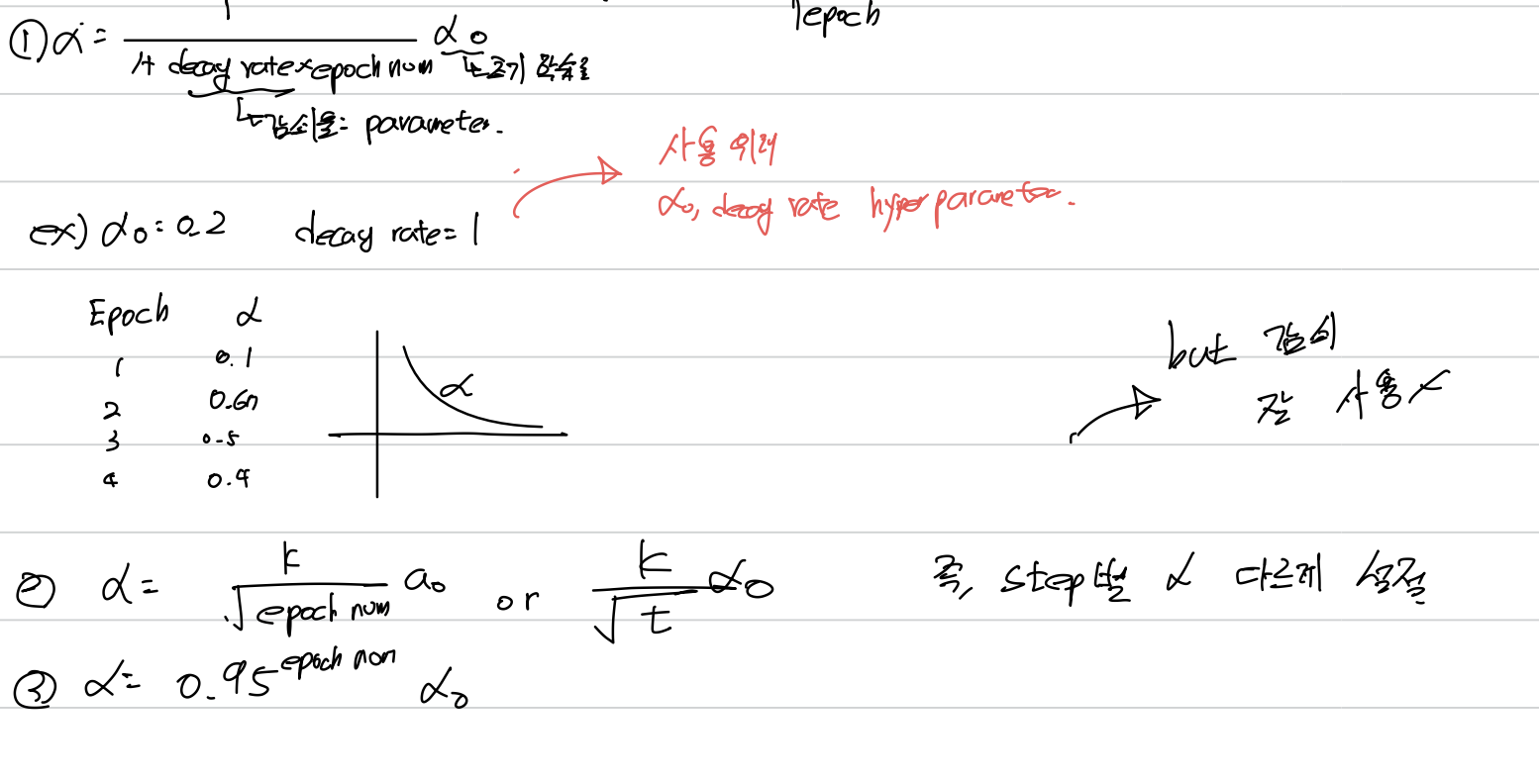
1.8 학습률 감쇠(Learning Rate Decay)
학습 알고리즘의 속도를 높이는 법은 시간에 따라 학습률을 천천히 줄이는 것이다.

작은 Mini-Batch에 Mini-Batch Gradient 사용 시 noise가 존재하며 줄어드는 경향은 있지만 최적값 수렴에는 어려움이 생긴다.
따라서 학습률을 조금씩 줄여가면 초반에는 큰 step으로 진행하며 갈수록 최적값 주변에서 조금씩 찾아가기에 더 빠르게 수렴할 수 있다.
2. 하이퍼파라미터 튜닝
2-1. 하이퍼파라미터 튜닝 프로세스

2-2. 적절한 척도 선택하기

3. 배치 정규화(Bath Normalization)
3-1. 배치 정규화
배치 정규화는 하이퍼파라미터 탐색을 쉽게 만들어주며, 신경망과 하이퍼파라미터의 상관관계를 줄여준다.
보통 활성화 함수 이전에 사용된다.


Z가 항상 같은 분포를 가지는 것은 별로이기 때문에 Z~를 학습시킨다.
다양한 최적화 알고리즘을 통해 r, B 설정 가능.
즉, input X를 정규화 하듯 은닉층까지 정규화 하는 것이 배치 정규화이다.
은닉층은 r과 B로 조정될 수 있는 평균과 분산을 가지도록 정규화한다.(은닉 유닛 별 평균과 분산 다르게)
3-2. 배치 정규화 적용시키기

3-3. 배치정규화가 잘 적용되는 이유
a. 배치 정규화는 입력 X값의 평균을 0, 분산을 1로 만들어 학습속도를 빠르게 한다.
b. 배치 정규화는 이전 층의 가중치 영향을 덜 받게 한다. 은닉층 값의 분포 변화를 줄여, 입력값의 분포를 제한하기에 입력값이 바뀌어 발생하는 문제를 안정화시킨다. 이에 층간 매개변수의 상관관계를 줄여 학습속도를 향상시킨다. 즉, 해당 Layer 관점에서 앞선 층의 값이 변화해도 배치 정규화 덕에 변화를 덜 느낄 수 있다(평균과 분산이 동일하도록 적용받았기 때문)
c. 미니배치로 계산한 평균과 분산은 전체 데이터의 일부로 추정해 잡음이 있다. 약간의 정규화 효과가 생긴다.
d. 드롭아웃에서는 곱셈 잡음이 있고, 배치 정규화의 경우 곱셈잡음과 덧셈잡음이 모두 있다. 따라서 드롭아웃처럼 약간의 정규화 효과(은닉층이 하나의 유닛에 너무 의존하지 않도록 하는) 가 생긴다.
3-4. 테스트시의 배치 정규화
배치 정규화는 한번에 하나의 미니배치를 적용하는데 테스트 시에는 하나씩 사용한다.
미니 배치화의 정규화 수식

test 과정에서는 이처럼 평균과 분산을 계산할 수 없기에 다른 방법이 필요하다.
테스트에서 적용하는법: 독립된 평균과 분산의 추정치를 구해서 사요하면 된다. 여러 미니배치에서 나온 지수가중평균을 추정치로 사용한다.

4. 다중 클래스 분류
4-1. Softmax Regression
Softmax Regression은 여러개의 클래스 분류 시 사용한다.

4-2. Softmax 분류기 학습시키기

해당 내용은 네이버 부스트코스 Andrew NG의 딥러닝 2단계: 심층 신경망 성능 향상시키기를 바탕으로 작성된 글입니다.