
Abstract
심리학 연구에서 시각적 특성(visual features)과 의미적 내용(semantic conetnt)가 다양한 감정을 전달할 수 있다는 것을 보여준다. 더 나아가, 연구들은 image emotion과 aesthetics(미학: 화풍/ 스타일 등)이 매우 밀접하게 연결되어 있는 것을 입증했다. Image Aesthetic assessment process(IAA: 이미지 미적 평가 과정)에서 이미지는 개인의 감정적인 반응을 이끌어내어 정서적인 공감을 이끌어내고, 이미지의 평가에 영향을 미친다.
본 논문에서는 Hypernetwork of emotion fusion(HNEF)를 통해 Image aesthetics(이미지 심미성) 평가 방법을 제안한다. 이 방법을 달성하기 위해, aesthetic과 emotion feature를 image로부터 추출한다. 추가적으로, Transforemr의 self-attention 기법을 통해 aesthetics와 emotion 사이의 밀접한 연관성을 포괄적으로 조사한다.
그리고, Hypernetwork는 이미지의 high-level 의미 정보에 대한 perception rules(지각 규칙)을 수립하기 위해 설계되었다. 실험 결고, 감정과 미학 간의 강력한 상관 관계를 검증하고, 기존 Aesthetic Visual Analysis Dataset에 적용한 방법론들과 비교했을 때 높은 성능을 보인다.
Introduction
과학 기술의 발전과 전자 기기의 발전으로, Visual Data가 급증하고 있다. 사람들은 사진과 동영상 공유를 통해 자신의 감정을 표현하는데 전자기기를 사용하는 경향이 증가하고 있다. Flickr, Facebook과 같은 수많은 웹사이트는 사용자를 유인하기 위한 수단으로 이미지를 사용한다. 다양한 품질의 이미지가 넘쳐나는 사황에서, automatic image aesthetics assessmet는 불가피하다. Automatic AAI는 Computer Vision task로 자동으로 image의 beauty를 평가하는 방식이다. 이는 이미지의 quality와, 아름다움에 대한 사람의 인지와 지각을 시뮬레이션하여 진행된다. 이는 Image ranking, 검색, 추천, 향상 등 다양한 분야에 널리 활용된다.
General Image Aesthetics Assessment(GIAA)는 majority of people이 image aesthetic에 전반적으로 인식하는 것을 의미하며, Personalized Image aesthetics Assessment(PIAA)는 개개인의 user가 느끼는 이미지에 대한 미적 인식을 의미한다.
원래, Image aesthetics에 대한 연구는 주로 GIAA에서 일어났다. 초기 연구들은 photographic rule에 기반해, 노출, 채도, 피사계 심도 등의 특성을 수동으로 추출해 Image aesthetic를 평가했다. 하지만, 이렇게 수동으로 feautre를 추출하는 것은 인간이 인지하는 복잡하고 추상적인 visual aesthetic를 포착하는데 한계가 있다. 그렇기에, 연구자들은 Deep Neural Network로 시선을 돌려,뛰어난 학습 능력을 활용하고자 했다. 이러한 Network는 다양한 얕은 특징을 학습하고 그들을 점수로 변환하는 것 뿐 아닌, Image의 내용을 표현하기 위한 high-level semantic(의미)를 capture해서 이미지를 평가할 수 있다. 그 후, 연구자들은 개인의 선호도가 있는 content attributes와 연관된 PIAA works가 제안되었다.
이러한 방법들의 성과에도 불구하고, Image aesthetic과 관련된 사용자의 주관적인 특성을 완전히 고려하지는 못했다. 심리학에서는 Image Emotion과 Aesthetic 사이에 밀접한 관계가 있다고 한다. Image emotion은 심리적인 공감을 불러 일으키고 Image aesthetics에 영향을 줄 수 있다.

심리학에서, Image emotion은 8가지 Categories로 구분된다. Fig 1에서 보면 윗줄은 4가지 positive emotion, 밑줄은 negative emotion을 포함한다. 예를 들어, 웃는 표정을 한 사람의 사진을 보면, inexplicatble sense of excitement를 느낄 수 있고, 곤충을 보면 무의식적으로 disgust(혐오감)을 느끼는 경우가 있다.
Aesthetic emotion은 인간 사회의 발전 과정에서 발생하는 spiritual need(영적 욕구)와 관련된 심오한 정서적인 경험이다. 시간이 지남에 따라, 학자들은 시각 예술(visual art)과 심리학의 영역에서 영향을 얻어, aesthetic과 감정의 계산적 측면을 이미지 분석을 통해 정의하고 탐구해 왔다. Emotion과 Aesthetic의 의미론적 특성으로 인해, 연구자들은 Image와 Image가 이끌어내는 감정과 aesthetic 사이의 연관성을 확립하려고 시도한다.
Image Emotion Recognition과 Image aesthetic 분야에서 광범위한 연구가 이뤄지고, 분야를 발전시켰다. 기존의 연구들은 Aesthetic과 Emotion 지각 사이의 상호작용을 인정한다. 하지만, 두 작업 사이의 internal relation은 완전히 탐구되지 않았다.
현재, attention mechanism이 효과적인 solution으로 떠오른다. 이는 대량의 pool에서 소수의 주요 정보를 선별하여, 네트워크가 이 중요한 데이터에 집중하고, 덜 중요한 세부 정보는 무시하도록 한다.
Attention 기법의 변형인 Self-Attention 기법은 외부 정보에 대한 의존도는 낮추고, 데이터 내부의 상관관계를 파악하는데 좋다.
본 논문에서는, 앞서 언급한 연구에서 영감을 받아, image emotion을 image aesthetic assement 과정에 통합해, HNEF에 기반한 새로운 방법을 제시한다. 추가적으로, Emotion과 Aesthetic 사이의 내적 관계를 탐구한다.
Countribution은 다음과 같다.
- Aesthetic과 Emotion 사이의 상호작용에서 영감을 바당, image aesthetic를 평가하는 hypernetwork framework를 제시한다.
- Image aesthetic를 평가하는 과정에서, 사용자의 주관적인 선호도가 철저히 고려된다.
- 이 방법을 이요하면, aesthetic과 emotional 정보를 모두 포함하는 추가 database가 필요하지 않다.
- Emotion과 Aesthetic에 연관된 고수준의 의미 정보를 고려해, rules of semantic perception을 획득하기 위한 hyper network를 구축했다.
- Trasnformer를 IAA Framework에 성공적으로 도입하고, 이를 활용한 fusion module을 개발했다. Transformer의 self-attention mechanism을 통해 Image aesthetic과 Emotion 사이의 본질적인 관계를 탐구한다.
Related Work
Image Aesthetic Assessment
1. GIAA:
3가지의 IAA task가 존재한다: Classification, Score Repression, Distirbution prediction
다양한 기존의 Image aesthetic 추론 알고리즘은, photographic principle과 같이 전문지식에 뿌리를 둔 feature를 사용했다.
Datta et al.은 일련의 manual feature를 manually design햇고, 이를 얕고 깊은 시각적 특징을 결합해 image aesthetic에 있어 이분법적인 작업을 진행했다
Yan et al.은 photographic knowledge를 기반으로 high level feature을 구성하여 Image Aesthetic를 평가했다.
이러한 방식들이 IAA에서 성공을 거두었지만, simple feature만으로 aesthetic of the image를 완전히 표현할 수 없다.
이후, CNN의 등장으로 IAA가 더 빠르게 발전했다. 강력항 abstract representation ability로 인해, network는 image를 이해하기 위한 high level 의미적 내용을 사용해 더 잘 이해할 수 있다. VGG 16, Inception-V2와 같은 우수한 framework가 효과를 입증했다.
Talebi et al.은 Basic CNN netowrk를 수정해 distribution of human opinion score를 예측해 Image aesthetic를 자동으로 학습하게 했다.
Ching et al.은 Self supervised 학습 기반을 바탕으로 photography rule과 visual saliency를 사용하는 방법을 학습했다.
Wang et al.은 Aesthetic description of image를 예측하기 위해, semantic addition transformation에 기반한 feedback network framework를 제안했다.
하지만, CNN은 고정된 size의 input을 받기 때문에, 이미지는 reiszed되거나 cropped 되어, Image 자체의 deatil을 잃어버리거나 Image의 beauty가 파괴된다. 이러한 문제를 해결하기 위해 multi-patch network가 제안되었다.
Chen et al.은 이미지의 종횡비를 유지하고, 모든 크기의 input image를 수신할 수 있는 adaptive fraction dilated convolution을 개발했다.
Ma et al.은 전체적인 이미지 layout과 세밀한 디테일의 손실을 고려해 이 둘의 혼합 정보를 추출할 뿐 아닌, 어떤 크기의 input도 수신할 수 있는 multi-patch network를 제안했다.
2. PIAA
Image 자체의 특성을 추출하는 것 아닌, user 개인의 uniqe한 선호도를 조사하는 것 역시 관심을 끌어 왔다.
Ren et al.은 일반적인 image aesthetic에서 벗어난, adaptive scheme of individual perception을 제안했는데, 이는 전체적인 aesthetic score를 평가하기 위해, user's uniqueness를 채택했다.
Zhe et al.은 PIAA를 small sample problem으로 간주하고, 각 사용자의 aesthetic 평가를 위함 광범위한 visual aesthtic으로부터 사전 지식을 학습하는 독립적으로 PIAA task를 진행했다.
또한, 사용자의 주관적인 특징과 이미지의 객관적인 특징을 통합한 PIAA 방법을 제안하고, 사용자의 characteristic과 image aesthetic attribute를 표현하기 위한 attribute extraction moduel이 제안되었다.
Wang 등[35]은 메타 학습 프레임워크를 사용하여 이전의 사용자 상호작용을 대체하고 소수의 주석이 달린 샘플을 사용하여 효과적인 개인화 학습 모델을 생성했다.
Li 등[36]은 multi task learning framework의 맥락에서의 주관적 선호도에 영향을 미치는 성격의 중요성을 조사했다.
Emotion and Aesthetics
심리학 연구는 image는 이미지의 시각적인 특성과, 의미적(semantic)내용에 따라 다양한 감정을 불러일으킬 수 있음을 시사했다. Image 감정인식은 이미지 검색 및 aesthetic prediction에 광범위하게 사용된다.
Datta et al.은 aesthetic(미학)의 격차를 연구하고, natural image에서 aesthetic과 emotion 추론의 주요 측면에 대해 논의했다.
Joshi et al.은 Visual Art와 심리학을 바탕으로 이미지에서 미학과 감적의 계산적인 추론의 핵심 측면을 정의했다.
Chen et al.은 Multi task learning을 기반으로 Image aesthetic과 emotion 사이의 내적 관계를 탐구하고, 관련 데이터셋을 제안했다.
Miao et al.은 Image aesthetic과 emotion 사이의 correlation matrix를 구축했다. 이는 Target recognition과 Scene Recognition에 기반한 semantic tag(의미태그)로 진행했다.
이렇게 많은 선행 연구가 많은 contribution이 있지만, 본 연구는 image content를 semantic tag 없이 바로 emotion conent에 바로 연결하기에, 데이터셋을 별도록 구축 할 필요가 없다.
또한, 많은 연구들은 emotion과 aesthetics가 긴밀하게 연결되어 있다고 한다.
Yang et al.은 새로운 Rich attribute personalized image aesthetics database(PARA)를 도입하여, personalized image aesthetic에 대해 가장 포괄적이고 주관적인 연구를 진행했다. 이는 aesthetic score가 2보다 작은 것들은 negative emotion을 전달한 가능성이 더 높다는 결론을 내렸다. 반대로, scorer가 높으면 subject에서 positive emotion을 전달한다.
Image와 Aesthetic는 밀접한 관련이 있지만, 그들의 주관적인 특성으로 인해 일반적으로 독립적인 작업으로 취급된다. 그렇기에, 본 연구에서는 aesthetic과 emotion을 통합해 그들의 interconnection을 더 깊이 이해할 것을 제안한다.
Proposed Method

본 논문은 Image Aesthetic를 평가하기 위해, Emotional Feature를 통합하고, 높은 수준의 의미론에 대한 Peceptual Rule를 학습하는 Adaptive hypernetwork learning framework를 제안한다.
Emotional Factor를 포함하므로써, Image aesthetic과 Emotion 사이의 correlation을 파악하고, 더 복잡한 aesthetic evaluation model을 개발할 수 있다.
본 model을 3가지 sub-network를 포함한다: Feature extraction, sematntic perception, aesthetic prediction
- Feature Extraction: 알고리즘은 Aesthetic, Emotional feature를 Image로부터 추출한다.
- 그리고, Self-attention mechanism이 aesthetic과 emotional element 사이의 internal relationship을 탐구하기 위해 적용된다.
- Semantic perception stage에서, aesthetic semantic perception hypernetwork를 구축하여, aesthetic prediction network로 가는 길을 안내한다.
- Aesthetic prediction stage에서, Image의 aestic, emotional feature를 결합한 combined feature를 aesthetic prediction network로 보내, aesthetic quality를 추정한다.
A. Feature Extraction Network
기존의 심리학 연구는 Aesthetic과 Emotion이 분리될 수 없는 관계임을 입증했다. 연구자들은 Aesthetic, Emotion, low level image composition 사이의 관계를 조사하며 이 복잡한 문제를 조사했다. 또한, High level semantic feature 역시 emotion과 aesthetic에 영향을 주는 것으로 관찰되었다.
본 논문에서는 Image의 Aesthetic과 Emotion Feature를 추출하고, 그 관계를 조사하여 Image의 aesthetic를 예측하는데 활용하고자 한다.
1. Aesthetic and Emotion Feature
Aesthetic, Emotion Feature은 Imagenet으로 pretrained된 ResNet50을 HNEF backbone으로 사용해 추출한다.
Image Aesthetic에 있어서, multi-scale content feature과 high-level semantic feature를 추출했다.
- Multi-scale content feature: 다양한 크기의 객체들에 대한 정보 캡쳐 가능: 작은 객체를 위해서는 작은 커널, 큰 객체를 위해서는 큰 커널. 이렇게 multi scale content feature를 사용하면 이미지의 다양한 크기와 형태의 객체에 대한 특징을 효과적으로 capture하여 다양한 시각적 작업에 활용 가능.
- ResNet50의 마지막 2개의 layer 삭제
- 56x56, 28x28, 14x14, 7x7 size의 feature을 layer_1,layer_2,layer_3,layer_4에서 추출한다.
- Image의 Local detail을 포착하기 위해, detail perception module을 통해 multi scale feature를 추출한다
- 구체적으로, feature mapping의 각 layer는 non-overlapping block으로 나뉘며, channel dimension을 따라 1x1 convolution으로 쌓이고, global average pooling으로 vector로 pool된다.
- 마지막으로, 이렇게 얻은 feature을 emotional feature와 연결한다.
- High-Level semantic feature는 layer 4의 feature이다.
- ResNet50의 마지막 2개의 layer 삭제
- Image Emotion Feature
- ResNet 50의 마지막 열을 8개의 emotion classification task를 진행한다. Cross Entropy Loss로 진행
- Pretrained network가 emotion task에 적용된 후, emotional feature를 추출하기 위해 network parameter는 frozen된다.
- 또한, 마지막 두개의 레이어를 삭제하고 mean pooling을 추가해 최종적으로 2048 차원의 emotional feature를 얻는다.
- 마지막 두개 삭제 이유: pooling layer, fully connected layer?
2. Feature Fusion Module
Aesthetic과 Emotional Characteristic의 internal relationship을 탐구하기 휘해 Feature Fusion Module이 Design 되었다.
Aesthetic과 Emotional feature가 각각의 feature extrator로부터 추출되었기에, 그들의 분포는 비교적 독립적이다. Aesthetic과 Emotional feature를 동시에 학습하기 위해, internal relationship을 탐구하기 위핸 fusion model를 도입한다.
Feature Fusion module은 Vision Transformer(ViT)를 기반으로 한다. Feature Fusion module은 Multi-head self attention, Multi-layer perception(MLP) 블록이 번걸아가며 구성된다. 그리고, residual connection 전에 layernormalization을 진행한다.
Channel connection을 통해 aesthetic과 emotion feature을 갖춘 400-dim feature를 얻고, 이를 Transformer과 encoder에 공급하여 representation을 얻는다.
Step 1. Connected feature는 attention mechansim에 적용된다.

Step 2. Multi-Head attention이 다른 sub space의 attention 정보를 병합해, 서로 다른 subspace간의 internal relationship을 파악한다.

Step 3. Multi Head Attention으로 얻어진 feature는 FeedForward Netowrk로 전송된다. FFN은 2개의 FC layer와 activation function ReLU를 포함한다.

400 차원 벡터는 트랜스포머의 인코더 후에 얻는다. 그 후 트랜스포머의 끝은 출력을 위해 FC 레이어(FC-224)를 사용합니다. ReLU와 0.3의 드롭아웃은 FC-224 레이어 다음에 사용된다.
B. Semantic Perception Hypernetwork
Hyeprnetwork는 하나의 network(hypernetwork)를 통해 다른 network의 가중치를 만들어 내는 방식으로, Image editing, Neural architecture search, meta learning 등등에 사용된다. 또한, Hypernetwork는 초기 Stable Diffusion을 채택함 Novel AI에 의해 개발된 fine-tuning 기법이다. 이는 Stable Diffusion model에 연결된 small neural network로 그 style을 수정하는데 사용된다. 본 눈문에서는 Image content에서 aesthetic perception(미적 지각)으로의 mapping을 simulate 한다. 이를 통해, 다른 image로부터 다른 aesthetic feature를 추출할 수 있다.
Hyeprnetwork는 3개의 convolution과 Weight/bias를 생성하는 4개의 branch로 구성된다.
우리는 Feature Extraction network에서 추출된 advanced aesthetic feature을 hypernetwork로 보낸다. Feature는 3개의 1x1 convolution layer를 통과 후, prediction network에 해당하는 weigh와 bias를 구성하기 위해 branch로 보내진다.
Weight는 3x3 convolution 이후 재구성되고, bias는 global average pooling과 fully connected layer를 통해 학습된다.
Hypernetwork의 크기 설계에 잇어서, predicted network의 layer 크기에 따라, output channels of convolution layer와 FClayer의 출력 채널을 결정한다. 생성된 weigh는 Image aesthetic의 perception rule로 간주되어, prediction network가 image aesthetic을 예측하도록 한다.
C. Aesthetic Prediction Network
Aesthetic Prediction Network는 Image의 Aesthetic Score를 계산하는 것이 목적이다. 4개의 FC layer를 포함하고, 각각의 activation function은 sigmoid를 사요한다.
최종 aesthetic score는 Input feature과 hypernetwork에서 생성된 weight에 의해 생성된다.

Experiments
A. Experimental details and Datasets
1) Experimental Detail:
ResNet50 pretrained on ImageNet이 backbone network로 사용되었다.
AVA, FI dataset이 network를 학습하기 위해 사용되었다.
Image size는 224 x 224 x 3으로 적용해 네트워크에서 사용했다.
Network Training: hypernetwork와 다른 network의 initial learning rate는 2e-4, 2e-5로 설정되며, learning rate는 5 epoch마다 이전 수준의 0.1배로 떨어진다
OptimizerL Adam, weight decay 5e-4
MSE Loss 사용, total 50 epoch
2) Dataset
- AVA
- IAA의 benchmark dataset으로 DPChallenge website에서 다운로드 가능
- 255000개 이상의 Image가 있으며, 963개의 challenging topic 다룰 수 있다.
- 각 image에는 aesthetic score가 1~ 10점의 미적 점수가 200여명의 투표자로부터 부여되어 있다.
- 일부 사진의 손실로 252423개의 사진을 down 했다.
- 20% Test set, 80% Train set
- Biniary classification task에서 평균 점수가 5점 이상은 1, 5점 미만은 0으로 표시했다
- Flickr and Instagram
- Flickr와 Instagram에서 제공한 약 23000개의 emotion image가 포함되어 있다.
- 이 dataset은 entertainment, anger, awe, satisfication, disgust, excitement, fear, sadness 8개의 감정 포함
- Emotion 6:
- 1980개의 사진, 6개의 감정(anger, disgust, fear,joy,sadness,surprise)
- 각 category에는 330개의 사진이 있으며, 각 사진은 15명의 실험자가 투표한다
- Artphoto:
- 3개의 dataset 활용한다: International Affective Image System(IAPS), a collection of art photos sourced from photo sharing websites, set of abstract paintings tat have been rated by peers
- 이 데이터셋에 사용된 사진들은 professional artist가 촬용한 것이다.
- 총 806장의 사진으로 구성되었으며, 8개의 감정 category로 분류됨
- Abstract
- 특정 사물을 묘사하지 않은 279개의 abstract painting으로 구성되어 있으며, 8개의 emotion category로 분류할 수 있다.
- 약 230명의 사람들이 투표했으며, 각 그림의 평균 점수는 약 14점이다.
B. Evaluation
기존 연구와 비교하기 위해, 전체 정확도(ACC), Spearman rank order correlation coefficient(SROCC), 피어슨 선형 상관 계수(PLCC), sequared earth movers distance(EMD)를 사용했다.
ACC는 올바르게 예측된 샘플의 비율이다.

ACC가 높을수록, classification performance가 높다고 할 수 있다.
SROCC와 PLCC는 Preidicted score와 subjective score(주관 점수)간의 일관성을 파악한다.
각각의 image에 대한 subjective score가 s_i, objective quality score가 p_i일 때, SROCC와 PLCC는 다은과 같다.

EMD는 model이 aesthetic distribution을 잘 예측하는지에 대한 평가 점수이다.

낮을수록 좋음
C. Overall Performace Comparison
3가지 방식으로 본 논문에서 제안한 방법론을 비교한다.
- ACC index: Binary classification에 있어서 Model의 Performace 측정
- SROCC, PLCC: Score Regression: 주관적 및 객관적 점수의 일관성과 단조성을 판단하는데 사용
- EMD: 모델의 분포 예측 능력 평가
우리는 제안된 방법의 성능을 세 가지 방법으로 확인합니다. 이진 분류의 경우 모델의 성능은 ACC 지수로 평가됩니다. 점수 회귀의 경우 SROCC와 PLCC가 주관적 및 객관적 점수의 일관성과 단조성을 판단하는 데 사용됩니다. EMD 값은 모델의 분포 예측 능력을 평가하는 데 사용됩니다.
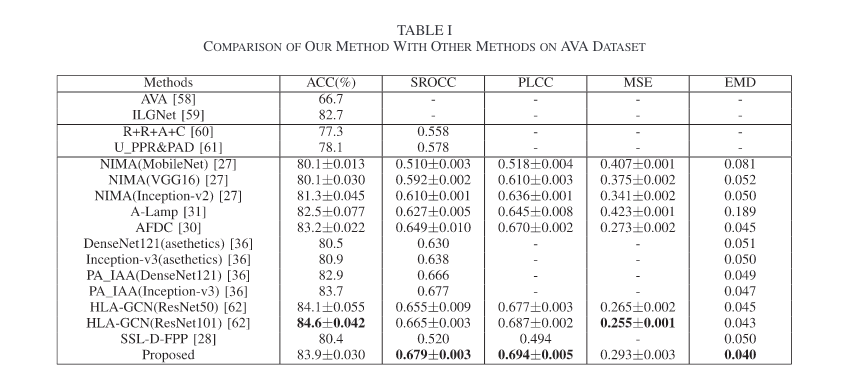
가장 좋은 값이 bold체로 되어있다.
Emotion based Image Aesthetic Evaluation method의 효과를 추가로 검증하기 위해, FI dataset를 emotion6, Abstract, Artphoto 등의 기타 데이터셋으로도 실험을 진행했다. 실험결과는 다음과 같다.

표에서 W/O emotion은 제안된 방법에 따라 감정이 제거된 것, Emotion6, Abstract, Artphoto는 emotion dataset FI를 대체해서 나타난다. fig의 결과에 따라 without emotion module보다 모두 성능이 크게 향상됐으며, 이는 emotion 기반의 image aesthetic evaluation method가 실현 가능함을 보여준디ㅏ. 하지만, Abstract는 dataset이 너무 적기에 without emotion보다 떨어진다.
반면, number of emotion dataset으로 인해 Emotion6가 가장 높은 성능, Arphoto, Abstract 순으로 순서가 나왔다.
이러한 현상은 데이터의 양이 deep network training에 미치는 영향이 크다는 것을 보여준다.또한, modeld의 generalization을 개선 할 필요가 있다.
Distributed prediction tast에서의 model의 성능을 보여주기 위해 Fig.3에 몇가지 예가 나와있다.

a,b,c,d,e는 5개의 이미지와, 그에 해당하는 aesthetic distribution을 보여준다. GT는 이미지의 Ground-Truth distribution을 보여주고, Pred는 model에 의해 예측된 distribution을 나타낸다.
Image의 Prediction 분포와 실제 label 분포가 일치하는 것을 명확히 알 수 있다. 또한, 문자와 밝은 색상이 있는 이미지의 분포는 일치하는 반면, 건축물이 있는 이미지의 분포는 일치하는 것이 흥미로운점이다. 이는 Network가 건축물이 있는 이미지보다, 문자와 밝은 색상이 있는 부분이 emotional feature을 추출하기가 더 쉽기 때문인 것으로 추정한다. 또한, 캐릭터와 밝은 색상의 이미지가 emotional feature를 전달하기 더 쉽다는 것을 보여준다.
추가적으로, Table 1에 대한 Wilcoxon Rank Sum Test를 진행했고, 각각의 metric h-value와 p-value가 Table 3에 나타나있다.

위의 표에서 다음과 같은 결론을 얻을 수 있습니다.
1) 윌콕슨 순위 합 테스트 결과의 h값은 모두 1로, 제안한 방법은 다른 방법에 비해 상당한 장점이 있음을 나타낸다.
2) 제안한 방법의 우수성은 ACC, SROCC, PLCC, MSE 등 다양한 관점에서 추가로 입증되었다.
D. Analysis of Aesthetics and Emotion
Image aesthetic과 Emotion 사이의 밀접한 관계를 파악하기 위해, 8 종류의 Emotional image에 대해 aesthetic score를 계산한다. 각각의 이미지에 대해 score는 1~10점으로 나타나 있다. 그리고, 각 Emotional 카테고리별로 다른 점수를 받은 이미지의 수를 계산해 Fig 4에 나타냈다.
Emotional Categories는 Positive, Negative로 나뉜다. Positive(Amusement, awe, contentment, excitement) Negative(anger,disgust,fear,sadness)

표에 따르면, Positive Image가 더 높은 Aesthetic score를 가지는 경향이 있고, Negaive Emotion은 Low Aesthetic score를 가지는 경우가 있고, 5점 이하에 집중되어 있다.
즉, 높은 Aesthetic Score를 가진 Image는 Positive Emotion을 전달 할 가능성이높고, 낮은 Aesthetic Image일수록 Negative Emotion을 전달 할 가능성이 높다.
네가지 Positive Emotion에서 보면, Amusement와 Excitement가 다른 두가지보다 심리적으로 긍정적인 감정을 불러올 수 있기 때문에, 다른 두가지 감정보다 미적 점수가 높을 것으로 보인다. 마찬가지로 disgust는 sadness보다 더 낮은 aesthetic score를 나타내는데, 이는 disgust가 sadness보다 더 negative한 감정을 불러올 수 있기 때문이다.
추가적으로, 또한 긍정적 감정을 가진 이미지의 미적 점수는 4~8에 집중되어 있고, 부정적 감정을 가진 이미지의 미적 점수는 1~4에 집중되어 있다는 점도 흥미로운데, 이는 앞서 도출한 결론과도 일치한다.[40]
E. Experiments on Emotion Datasets
Image Emotion Recognition에서 본 논문에서 제안한 방법의 효과를 평가하기 위해 실험을 수행했따. Proposed method는 Image Aesthetic을 평가하기 위해 Emotion Fusion을 진행한 것을 바탕으로 한다.
Image aesthetic과 emotion의 관계를 봤을 때, 본 논문에서 제안한 방법은 Emotion Recognition에도 적합할 것으로 예상한다.
Advanved Image Emotion Recognition method를 FI dataset에서 수행한다. 이는 Training과 Testset의 분할이 AVA Dataset과 동일한 환경에서 수행된다.
Table 4는 예측 결과와 Complexity를 보여준다.

이중, SIFT, HOG, SentiBank는 manual method이고, 다른 방법은 Neural netork 기반이다.
전체적으로 보면, 본 논문에서 제안한 방법이 모든 방법보다 우수하고, ECO-CNN보다 1.19 높은 결과를 보여 Image Emotion Recognition에서 효과적임을 입증했다. 또한, Neural Network 기반의 CNN 기법이 manual method보다 우수하기에, 이는 Deep Neural network의 우수성을 입증한다.
Complexity 측면에서, 본 논문에서 제안한 Parameter는 Alexnet(Fine-Tuned), Binary Assisted보다 적다. EOC-CNN보다 복잡하지만, 이는 허용 범위 안에 있으며, 정확도 측면에서 이점을 가지고 있다.
또한, 다른 감정 dataset에서도 검증을 진행했으며, 이는 Table 5에 나와있다.

표의 Cross Datasets ACC 는 본 논문에서 제안한 방법의 학습 parameter weight를 사용해 다른 emotional dataset에 대한 실험 결과를 나타내며, Retraining ACC는 다른 Emotional Dataset를 Retrain한 후 수행한 실험 결과를 나타낸다.
표의 결과를 보면, 원래의 network weight를 사용해서 학습할 때, Abstract와 Art-Photo의 경우 Accuracy가 크게 떨어지는 것을 알 수 있는데, 이는 Emotional dataset의 수와 type의 차이로 나타나는 현상이다.
또한, 표에서 Emotion Datset을 Retrain한 경우, 정확도가 크게 향상되었으며, 특히 Emotion 6가 6%로 가장 많이증가했다. Abstract의 정확도가 떨어지는 이유는 AVA dataset 우와 격차가 너무 많이 나서 네트워크 학습에 어려움을 겪기 때문이다.
F. Visualization Experiment
Proposed Model에서 사용하는 Discriminant Image area를 시각화하기 위해 Grad-Cam을 사용했다. Fig.5는 Backbone network와 proposed network의 Prediction images aesthetic에 대한 Grad-Cam Image 영역을 보여준다. 첫째줄은 원본 이미지, 다음줄은 Backbone network의 Grad-Cam, 마지막줄은 Proposed의 Grad-Cam

이를 바탕으로 두가지 결론을 도출할 수 있다.
- From the top to bottom of the GradCAM image에서 보면, 이 방법으로 식별된 Recognition Area가 더 넓게 분포되어 이미지의 더 많은 영억을 커버하고있으며, 이는 Proposed 방법이 더 많은 것을 학습할 수 있음을 보여준다.
- Backbone Network의 경우, discrimination area가 더 aesthetic feature에 집중함을 알 수 있다. 예를 들어 이미지의 해상도 및 피사계 심도와 같은...
- Proposed Method는 Cat, characters와 같은 Entertainment Facilities에 더 초점을 둔다. chairs next to cats, light behind characters보다..
- 이러한 영역에는 Aesthetic Attribute 뿐 아닌, 감정을 포함하는 feature가 있을 수 있다,.
- 이러한 징후는, Proposed 가 Aesthetic 뿐 아닌, Emotional Feature역시 capture하고 둘 사이의 관계를 파악할 수 있다는 것을 보여준다.
G. Ablation Experiment
Proposed method의 각 모듈의 성능을 검증하기 위해, AVA dataset에 대해 ablation Experiment를 진행했으며, 표 5에 나와있다.

이 모델들은 모두 전체 네트워크가 Fine Tuned end to End로 된 ResNet50을 Backbone으로 사용한다. 공정한 비교를 위해 모든 experimental setup과 implementation detail을 동일하게 했다.
Resnet + Hyper는 Hyeprnetwork based on the backbone network of ResNet 50이다.
Resnet + hyepr + emotion은 proposed방법이다. 이전 Experiment들과 비교하면, Transformet moduledl cnrkehldjTEk.
Backbone network와 비교했을 때, hyper network의 SROCC는 약 0.3, Emotion,Transformer은 각각 0.1씩 개선되었다.
이는 Hypernetwork가 high level semantic perception rule을 학습하고, Transformer가 aesthetic과 emotion 사이의 관계를 잘 나타내는 것을 알 수있다.
각각의 module이 대체 불가능한 역할을 잘 수행하고 있다.
Conclusion
Hypernetwork of Emotion fusion에 기반한 IAA Framework를 제안했다. 이는 Image의 Aesthetic과 Emotion을 통합했다.
심리학에서 영감을 받아, 본 논문은 Emotion fusion을 제안했다. 이는 다른 이미지에서 불러일으키는 감정을 네트워크가 포착할 수 있도록 한다.
또한, Image Aesthetic과 Emotion 사이의 Internal relationship을 파악하기 위해 Transformer에 기반한 fusion model을 설게했다.
Image Aesthetic과 Emotion 내의 high level semantic inherent(내재된 고차원적인 의미)를 ㄱ마안하여, sematnic perception rule을 설립하기 위한 hypernetwork를 구축해, 예측 network로 안내한다.
궁극적으로 Prediction Network는 IAA network에 성공적으로 수행하고, 기존 framework보다 뛰어나다.
향후는 IAA에 대해 더 깊이 탐구하고, Generalization을 위해 노력할것이다.